Beyond Hash-Bangs: Reliance on JavaScript Is a Bad Idea
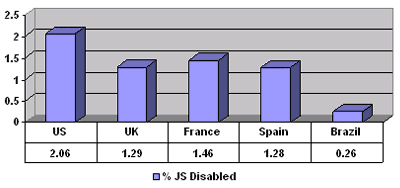
In November I wrote up a post (How Many Users Support JavaScript?) outlining the process and results from Yahoo’s study about how many users have JavaScript disabled (How many users have JavaScript disabled? and Followup: How many users have JavaScript disabled?).
The Numbers
In those articles, Yahoo stated that even using the meager percentage it found, that number corresponds to 20-40 million users across the internet. At 2009 census numbers, that’s the entire population of New York State on the low end or more than the entire population of California on the high end. That tiny percentage is no small number of users.
Before you think that all those users are sitting in parts of the world that don’t care about your product or service, Yahoo itself fields 6 million visits per month from users without JavaScript (whether it’s disabled or the browser doesn’t support it). That easily justifies Yahoo’s work to make the home page accessible to everyone.
Gawker and Twitter
In a very recent example of what an over-reliance on JavaScript can cause, on Monday the sites under the Gawker umbrella, Gizmodo, Lifehacker, iO9, and Gawker itself, all failed (Gawker Outage Causing Twitter Stir). And not in the typical way we’re used to seeing such as server 500 errors, timeouts, and other artifacts of generating too much traffic or pushing the wrong button. In this case the error was a function of a complete reliance on JavaScript to render the page. The sites are back up and functional, unless of course you have JavaScript disabled (this screen shot is from today):

The Gawker sites aren’t the only culprit. Twitter is another example. When I attempt to link to a tweet from last night about these issues, I can’t access the page at all with JavaScript disabled (turn off JavaScript and try it yourself). I just end up at the Twitter home page. Some other sites rely on so much JavaScript on top of the HTML that the page is constantly reflowing. One culprit is Mashable.com, requiring me to wait patiently while the page finishes drawing before I risk any interaction with the page for fear of an errant click.
How JavaScript Is Breaking the Web
Last night I came across a post, Breaking the Web with hash-bangs, which specifically references the Gawker downtime along with Twitter’s confounding page addresses. You might recognize the site (or author) because it’s the very same site that took issue with Yahoo’s methodology for reporting on JavaScript disabled users (Disabling JavaScript: Asking the wrong question). In that post he outlines other ways that browsers might report a lack of JavaScript support:
- The site serving the JavaScript file might be unreachable, a risk when relying on JS libraries hosted on third-party sites.
- The URL for the JavaScript file needs to be correct.
- The connectivity to the JavaScript file must exist, which means network lag, DNS issues, bad jumps, etc. can all break that path.
- An intermediary server passing that JavaScript file along could decide it is spam or malware, based on its own rules, and just purge the contents of the file.
- Other policies at the destination may strip the file or block it in some way.
In last night’s post he draws attention to the new reliance on page addresses that really only exist as fragment identifiers that are then parsed by JavaScript to return a particular piece of content. What this means is that in order to see the page, you have to not be in the 20-40 million number without JavaScript support and you have to successfully make it past the five items I outline above. Oh — and the JavaScript cannot have any errors. Some examples of JavaScript-related errors (from the article):
- JavaScript fails to load led to a 5 hour outage on all Gawker media properties on Monday. (Yes, Sproutcore and Cappucino fans, empty divs are not an appropriate fallback.)
- A trailing comma in an array or object literal will cause a JavaScript error in Internet Explorer – for Gawker, this will translate into a complete site-outage for IE users
- A debugging console.log line accidentally left in the source will cause Gawker’s site to fail when the visitor’s browser doesn’t have the developer tools installed and enabled (Firefox, Safari, Internet Explorer)
- Adverts regularly trip up with errors. So Gawker’s site availability is completely within the hands of advert JavaScript. Experienced web-developers know that Javascript from advertisers are the worst lumps of code out there on the web.
I feel so strongly about how poorly Gawker implemented its new sites, about how Twitter relies on the same approach, how it all relies on a hack in Google’s spidering technology in order to even make it into the search engines, that you really do need to go read this post, to which I am linking again: Breaking the Web with hash-bangs
For years I have tried to talk people out of relying on JavaScript for everything. I usually end up trying to explain the concept to someone who thinks it takes more time to build a site to not rely on JavaScript. Which is totally wrong. If all your forms validation is done via JavaScript, for example, then you are really putting yourself at risk (do you sniff for SQL injection attacks solely via JavaScript?).
JavaScript is a method to enhance your site (progressive enhancement), not replace features you should be building on the server and in your HTML. Relying on the end-user’s browser, and there are so many variations, to execute your JavaScript without generating an error (which all too often brings everything to a halt) just isn’t a very resilient approach to development. On top of that, how many developers really know how to build support for WCAG 2.0 into their JavaScript?
Without JavaScript there are a few sites on the web I cannot use at all, owing to their shoddy implementation practices and poor business decisions. On the bright side, surfing sites like Mashable without JavaScript means I don’t see any ads and the page render time increases dramatically. However, even with JavaScript enabled, poor scripting techniques still spare me the sight of those ads:
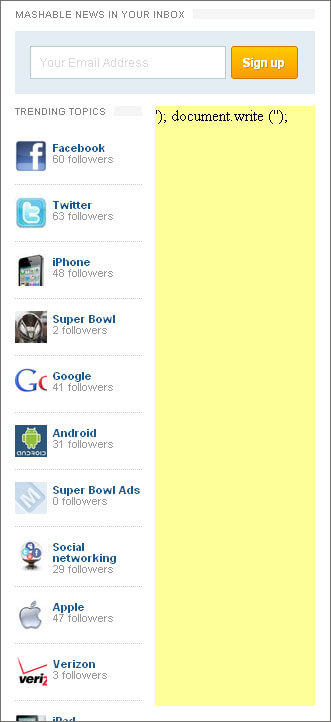
I would be willing to bet that this simple JavaScript error would have brought any of the Gawker family of sites down. And if the JavaScript is passed in from the ad service, the only recourse is to cut the ad altogether and lose the revenue.
Even at that most basic level you can see how poor of a decision JavaScript reliance is.
Updates: February 11, 2011
In the post Hash, Bang, Wallop the author provides some alternate views and arguments on how the hash-bang approach isn’t necessarily the wrong way to do things. His argument is compelling, until the end when he wraps up discussing users without JavaScript and users without quality internet access. His statement that JavaScript errors breaking execution can be almost entirely avoided with good development practices
presumes that end-users have any control and that the amount of errors we see now is an aberration — something my 15+ years of experience tells me isn’t true. He also talks about poor connections by saying that there are people daring to live somewhere in the world where packet loss is a problem
. I somehow suspect that Twitter users in Iran or Egypt might disagree that they dared to live there, or had a choice.
Two more articles railing against the reliance on hash-bang URLs, AJAX and JavaScript:
- Going Postel by Jeremy Keith.
- Broken Links by Tim Bray.
And for a little self-congratulation, this post was referenced in this week’s Web Design Update, something I have read for nearly its entire existence and hold with rather high regard. If you consider yourself a web developer and aren’t on this mailing list, you’re not really a web developer.
Updates: February 12, 2011
I found this script this morning which is designed to end the reliance on hash-bangs and the resultant URLs they force into page addresses: History.js.
History.js gracefully supports the HTML5 History/State APIs (pushState, replaceState, onPopState) in all browsers. […] For HTML5 browsers this means that you can modify the URL directly, without needing to use hashes anymore. […]
While this looks like a nice alternative to the hash-bang problem (which it is, not a solution), it relies on two things: the user having an HTML5-capable browser, and the JavaScript still executing despite everything I’ve outlined above.
In short, the wrong problem is being addressed here. The reliance on JavaScript is the issue, not just the methodology of that reliance.
Updates: June 1, 2011
The post It’s About The Hashbangs points out that hash-bangs’ use as a stop-gap until pushState is supported in browsers isn’t a valid reason to use them. He also addresses how hash-bangs break standard URL rules, confusing and confounding tried-and-true server-side processing methods. It’s worth a read.
Update: May 7, 2015
It’s 2015 and yes, this is still a thing. So I’ll just leave this here for your review: Everyone has JavaScript, right?
5 Comments
Interesting to note also, if you are an Google Analytics user, as visitors to your site who have JavaScript disabled won't have their visits reported.
Which is why I sometimes stealth-surf using Lynx. It won't get tracked in Analytics and nowadays nobody looks at web logs anymore.
Darn, I was going to do this on a new site. I guess I will use VRML instead.
Sweet. I'll break out my copy of Netscape Navigator 4 with the appropriate plug-ins so I can slow my machine to a crawl.
[…] chart: http://kryogenix.org/code/browser/everyonehasjs.html I gathered links in my own old rants: https://adrianroselli.com/2011/02/beyond-hash-bangs-reliance-on.html […]
Leave a Comment or Response