What Does X% of Issues Mean?
I ran a highly scientific and well-scoped Twitter poll (yes, sarcasm) to ask a question that has been in the back of my head for some time:
When you see a claim that an automated accessibility testing tool finds X% of issues, what do you believe the word ‘issues’ means in that context?
![]() Twitter polls allow up to four options, with each limited to 25 characters. The options I provided, along with the results:
Twitter polls allow up to four options, with each limited to 25 characters. The options I provided, along with the results:
| Options | Percent | Count |
|---|---|---|
| WCAG Success Criteria | 42.7% | 88 |
| SC Failures / Techniques | 15.5% | 32 |
| Some other public list | 3.4% | 7 |
| Tool’s own list of items | 38.3% | 79 |
Responses to the tweet were varied, with some asking for clarification on the options I provided. For the benefit of the reader, here is how I generally broke them down:
- WCAG Success Criteria
- The 78 Success Criteria from the WAI Web Content Accessibility Guidelines version 2.1, or some sub-set based on conformance level (A, AA, AAA)
- SC Failures / Techniques
- The Techniques for WCAG 2.1, which provides 90 different ways of failing assorted Success Criteria, along with dozens of techniques to pass them.
- Some other public list
- Assorted organizations publish their own testing parameters. For example, the UK Digital Services provides a WCAG 2.1 Primer that includes common mistakes (or failures). The DHS Trusted Tester program uses the Section 508 ICT Testing Baseline. Or perhaps another plain language take.
- Tool’s own list of items
- The automated checker might have its down rules. They conform to WCAG, but correspond to tests unique to the tool (hopefully influenced by the Accessibility Conformance Testing W3C Task Force).
Some interesting feedback came in. Amber suggested it can’t be the tool’s own list since it would be 100%, but Joe pointed out a tool’s tests may not be the same as its list of items. Paul gave an example where a vendor sub-divides WCAG into automatable and not. Alastair raised the complication of instances of issues, which speaks to challenges explaining this to management. Joppe posited it might be moot since the wording is intentionally vague. Dylan tossed out an approach for statisticians to ponder.
My Twitter poll is by no means scientific. With 206 responses it is well above the 100 person count a galaxy brain considers sufficient for a test. But it does show that the plurality of respondents might think a tool claiming it tests X% of something is testing X% of WCAG SCs. It might also be dramatically different and my Twitter poll wording was terrible. Which, in itself, confirms there is confusion.
Objectively, issues are not WCAG Success Criteria. Issues could be arbitrary. Issues could also be a function of density. Issues could include warnings. In fact, issues could really be anything if left undefined.
It also makes it harder to identify when somebody is stacking test results from vendors. That practice may artificially inflate bad scores with arbitrary and duplicate tests.
What’s the Verdict?
If vendors are pitching based on their ability to catch X% of issues on a page, ask them to clarify. Ask them to define issues. At the very least, put them on notice that you expect the marketing message to correspond with expectations, not mis-use them.
Update: 1 November 2023
At A11yTO Conference, Steve Faulkner gave a talk (“No industry for old men”), where he had a few slides that explain how the removal of Success Criterion 4.1.1 likely drops some claim percentages:


Mind Blown
We analyzed 13,000+ pages/page states, and nearly 300,000 issues and found that 57.38% of issues from first-time audit customers could be found from automated testing.
How was this achieved ??
From a consistent 30% to 57% almost double!!!
- Change the way the % is calculated
- Old = Total number of success criteria auto testable
- New = Number of instances of issues found of the autotestable criterion
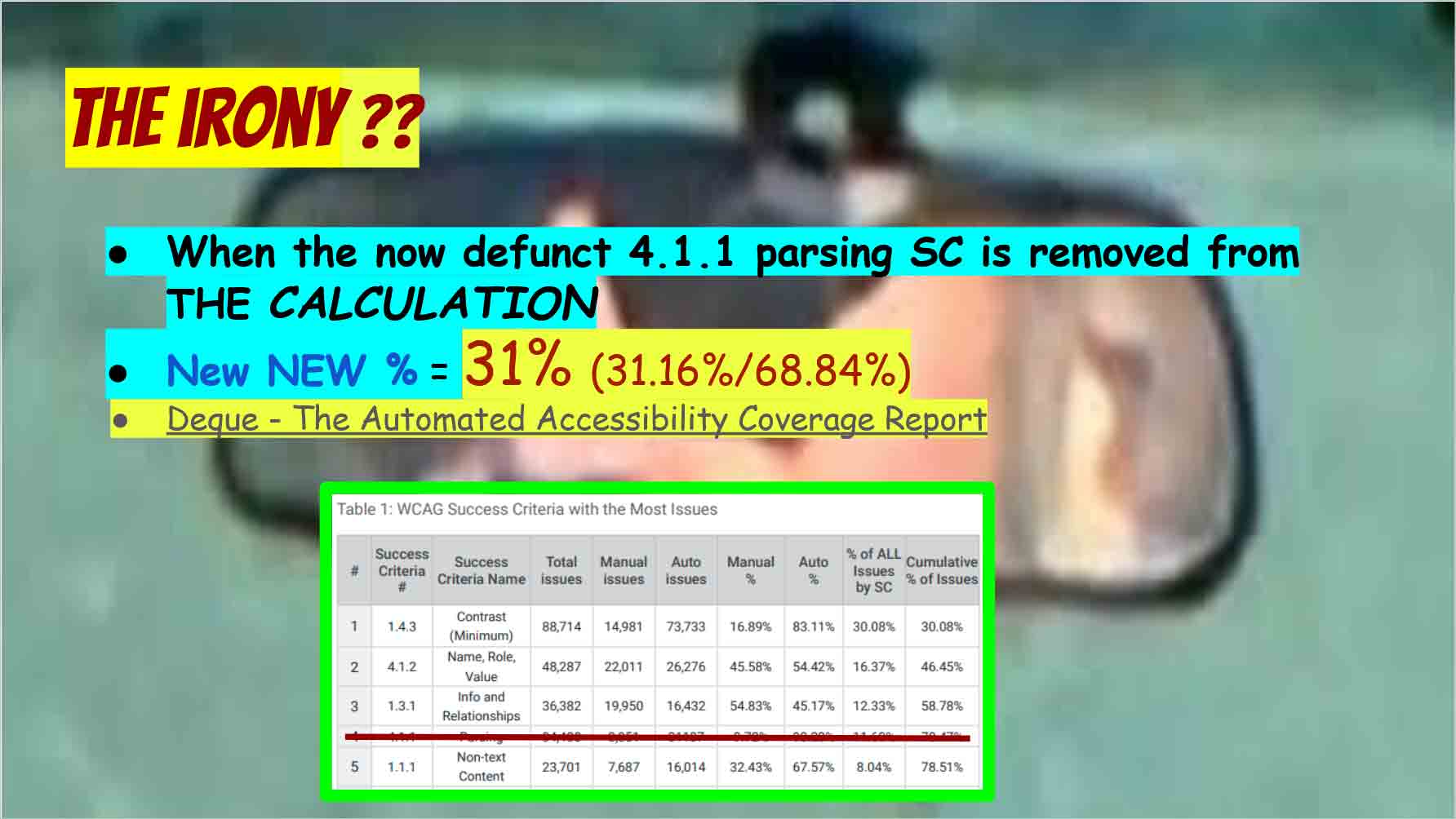
The irony ??
- When the now defunct 4.1.1 parsing SC is removed from THE CALCULATION
- New NEW % = 31% (31.16%/68.84%)
- Deque – The Automated Accessibility Coverage Report
[Me: the slide includes an image of “Table 1: WCAG Success Criteria with the Most Issues” from the linked Deque report and shows row 4, corresponding to SC 4.1.1, has been crossed out]
Essentially the argument is that you take the count of SC 4.1.1 issues that are picked up by the automated tools. Then you subtract from the total count of issues identified by the automated checker. This reduces the percentage of total issues to the roughly 30% that are generally accepted as automatically testable in WCAG, suggesting the marketed higher total may have been based on issues that had little to no impact on users and are now gone.
Of course, there may be more at play and those correlating numbers may simply be a fluke.
5 Comments
But it does show that the majority of respondents might think a tool claiming it tests X% of something is testing X% of WCAG SCs.
plurality
In response to . Fixed. Thanks!
[…] to What Does X% of Issues Mean? by Adrian […]
Even if you get universal agreement on this figure, it’s not particularly useful. Depending on what the actual issues are on a page, a tool might find between 0% and 100% of them.
The danger is that people will believe that the tool always finds X% of the issues on a page. They may consider that to be adequate. They may believe that they know how many issues the tool didn’t find, based on the number it did. This might sound like an obvious fallacy, but there are a lot of misconceptions regarding automated tools.
Also, choosing a tool with the highest value of X may not be the best idea. Tools use a mixture of rules (which should always give the correct result) and heuristics (which are fallible, but are expected to usually give the correct result).
As a rule, greater use of heuristics will result in a greater value of X, but will also result in more false positives. Tool selection needs to balance the two, not just look for the highest value of X. For instance, in some situations (such as in a continuous integration process) you can’t afford any false positives, so you would accept a low value of X.
In response to . Steve, checking the site in your bio I see that organizationally it appears you have also found the need to qualify automated tests, possibly for the same reason I wrote this post:
Automated tools can only test approximately a quarter of the 65 WCAG checkpoints. They can highlight the need for manual testing of some checkpoints, but for others they can make no assessment at all
Though WCAG 2.1 has 90 Success Criteria, I suspect you meant AA SCs there. That is not meant to pick on the site content at all, but instead it shows that even as an industry when we try to bring clarity we can still muddle it. I know I unintentionally do it all the time.
Leave a Comment or Response