XPath for In-Browser Testing
Chrome, Firefox, and Safari (the latter as confirmed by Al in the comments) support XPath searches when in the DOM view of their dev tools. Because the browser cleans whatever HTML it encounters (closing tags, correcting nesting), XPath can operate on the code as XML.
Simple checks like finding a unique ID value can result in multiple hits in the page (attribute references, script, partial matches, etc.). As a result, one of my most frequent XPath searches will bring me directly to the node with a given ID value (or tell me there is more than one).
//*[@id="VALUE"]
Essentially that statement is saying bring me to any node (*) anywhere in the tree (//) that has an id attribute ([@id…]) with a specific value ([…="VALUE"]).
This works for other elements and attributes. To adjust it, this will get me all nodes that are <input type="text">:
//input[@type="text"]
This will get me all nodes that are <input type="text"> that do not have an autocomplete attribute:
//input[@type="text"][not(@autocomplete)]
This will get me all nodes that are <input type="text"> that do not have an autocomplete attribute that are descendants of a <main> (to avoid contact forms in a footer, for example):
//main//input[@type="text"][not(@autocomplete)]
Breaking away from the form field example, this will cycle through all instances of a node with a tabindex value of 1 or more:
//*[@tabindex>0]
This returns instances of aria-labelledby that probably point to more than one thing (or just have an errant space character):
//*[contains(@aria-labelledby," ")]
Swap out aria-labelledby for aria-describedby, headers, or other attributes that accept space-separated values.
Annoying aria-label values that include interaction instructions with either “click” or “press”:
//*[contains(@aria-label,"click") or contains(@aria-label,"press")]You can find all instances of a particular inline style (you will need to tweak spaces and syntax to match what you want to find):
//*[contains(@style,"color: rgb(112, 129, 133)")]If you follow me on the Twitters you may recall when I asked folks to check for hits on this one:
//*[@aria-hidden="true"]//*[@aria-hidden="false"]
It was the quickest way I could think of to find cases of nodes with aria-hidden="false" living somewhere within a node with aria-hidden="true" (primarily to see if Angular is the only offender preventing this ARIA issue from ever going anywhere).
Let’s take a quick look in the browser.
Here I demonstrate the feature in Firefox to identify duplicated id values on a page:
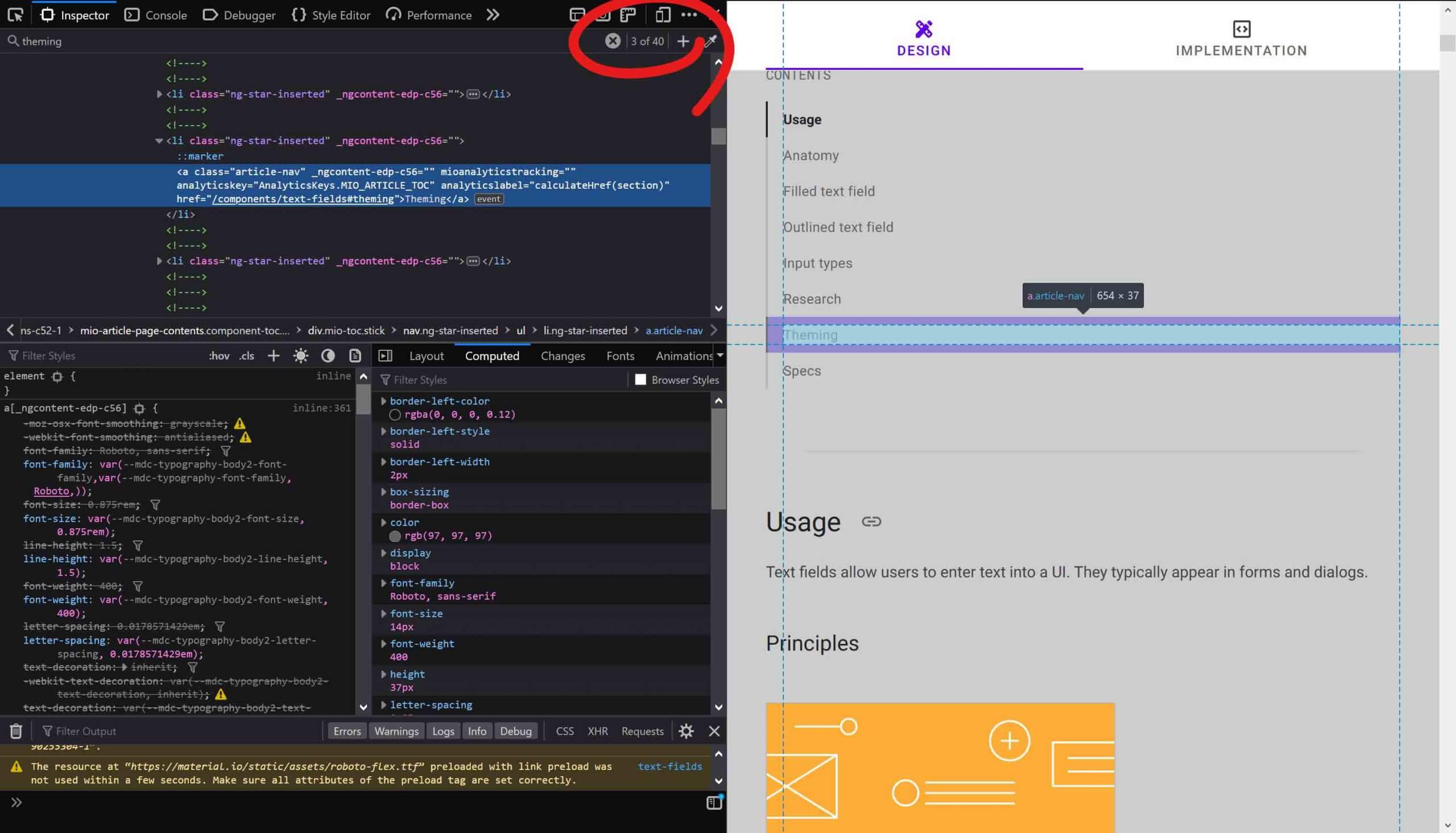
![Searching for ‟//*[@id="theming"]” and getting 2 results.](/wp-content/uploads/2021/04/XPath_ff-02-scaled.jpg)
id value because my accessibility tools told me so, but when searching for all instances of ‟theming” I get 40 results. Using //*[@id="theming"] gets me 2 results, a more manageable number.And here it is in Chrome:
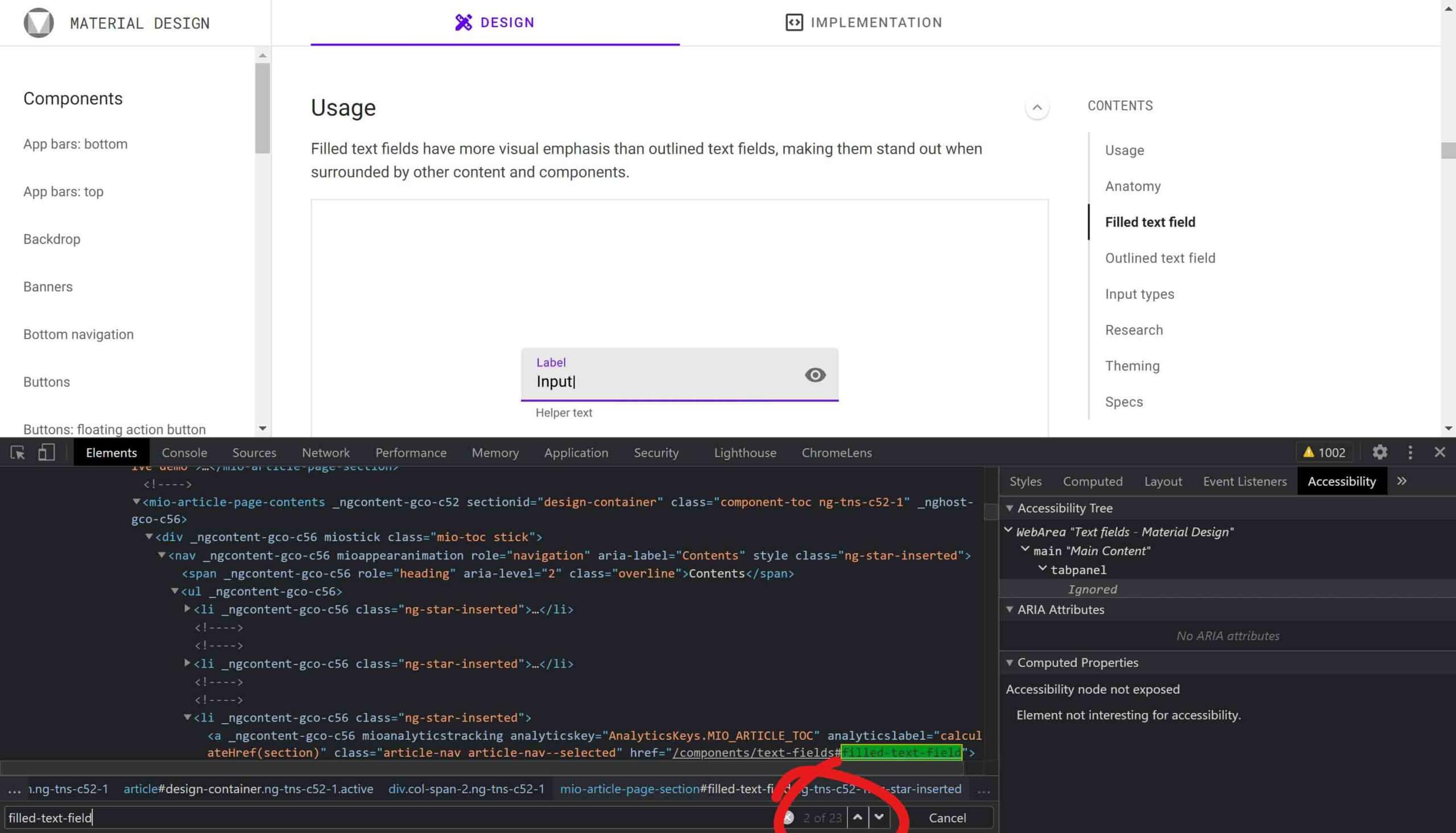
![Searching for ‟//*[@id="filled-text-field"]” and getting 2 results.](/wp-content/uploads/2021/04/XPath_chrome-02-scaled.jpg)
//*[@id="filled-text-field"] gets me 3 resultsIf you are far more comfortable with CSS selectors, Lloydi showed me this handy CSS selector to XPath converter.
That’s it. That’s the post.
Update: 27 April 2021
Tossing out some other variations that may help. Like this one which made it easier to find the live regions (turned out there were more than one) that were getting updated with the exact same text that appeared in a few other places on the screen in some deeply nested nodes:
//*[@role="status"]This syntax helped me quickly demonstrate a page had 26 script blocks:
//script[not(@src)]On the same page, this helped me quickly prove there were 157 calls to external scripts:
//script[@src]And confirm they were all loading from external domains:
//script[contains(@src,"//")]//link[@rel="stylesheet"]Update: 16 July 2021
Two updates today.
All ARIA Attributes
I was asked how to select all elements with ARIA attributes. Conveniently, all ARIA attributes start with aria- so that makes it a bit easier:
//*[@*[starts-with(name(),"aria-")]]This would also work with other prefixed attributes, like the ARIA roles specific to digital publishing:
//*[@*[starts-with(name(),"doc-")]]
Of course, it is much easier to select all nodes with the role attribute:
//*[@role]Case Sensitivity
XPath is case sensitive. This is important when trying to select nodes, since you need to match the case of any values. For example, the preceding heading is <h3 id="Case">. To select it by the id value I need to honor the capitalization:
//h2[@id="Case"]
I chose this example because you can open the dev tools on this page and test it. Now try it with a lowercase value, //h2[@id="case"]. You see it will not work. This should really only happen due to a typo or some artificial upper/lower-case conversion (such as if someone applied text-transform to this page and your browser copied the wrong styled version).
You might think you can get around it with either a case-insensitive selector, such as //h2[matches(@id,"case","i")]. Or maybe even by forcing the entire comparison to lower-case, as with //h2[lower-case(@id)="case"]. But if you give it a shot in your browser, no luck.
Aaron Smith at TPGi tracked down a nugget for me as I was trying to figure out why this would not work — current browsers only support XPath 1.0, and this technique is XPath 2.0. I later found a Firefox feature request from 2007 asking for XPath 2.0 support (in the overall platform, not just this feature) which was closed as WONTFIX in 2017.
If your workflow relies on XPath in the browser, then make sure you get your case right.
If/when you test on this page, note you will get string hits for the example code, but you won’t get a node hit. So don’t be confused.
Update: 31 January 2022
Sometimes you know the position of a node and can use [1], or whatever number, to get it. Sometimes you just want to get the button that lives somewhere in the last row of a table that is never the same number of rows when you visit it, so you use [last()]:
//table//tr[last()]//button
If you want the node that immediately follows the one you have, then following-sibling:: is your friend. If you wonder where you would use this, think of my simple disclosure widget example where the button toggles display of a block of content that immediately follows it. Alternatively, use preceding-sibling:: to select the disclosed content and then work backward to the button. Finally, you can walk up a node with .. — handy if the node you want is too generic but it has a unique descendant.
//button[@aria-expanded]/following-sibling::div
//div[@class="disclosee"]/preceding-sibling::button
//*[@aria-hidden="true"]/../..
Coming up against <label>s that are not associated with a field can be tricky to grab. Since they should have unique text, lean on the text node to grab the one you want with text(). You can pair it with contains() if you need to exclude redundant text (or more broadly select nodes).
//label[text()="First name"]
//button[contains(text(),"edit")]7 Comments
These DevTool interfaces also let you search by CSS selector, like
main input[type="text"]:not([autocomplete]), and has auto-complete capabilities that can be helpful. I used a little XPath, basically by rote, well over ten years ago and haven’t seen much reason to learn it.One thing the XPath version seems to do is clearly differentiate the DOM code from mere strings. In trying to find duplicate ids using just the CSS selector
#theming, the search also finds hers that end with that string; preceding it with an asterisk (* #theming) does seem to force it to match only the CSS selectors.
In response to . I also have dusty XPath skills from the previous decade (my company built a CMS that output XML, which we processed with XSLT to web and other formats), so yeah, it is a niche skill for me too.
But as I have seen more tools (things like Selenium or accessibility testing tool reporting features) lean on XPath, I have found myself dusting off those skills in response.
Is there a way to target nodes within a shadow DOM?
In response to . Bill, not as far as I know. If it is supported and you find the syntax, please drop a note here.
Neither Selenium nor WebDriver support it either (AFAIK).
There is a handy XPath cheatsheet at devhints.io/xpath but I have not tested how much of this is supported by Firefox.
Doing a deep dive into Xpath for a project; just wanted to give you a heads up it’s supported in Safari, too. I’m using it in Safari 26.5; it’s probably been hiding in Safari for years.
Thanks.
In response to . Well, will you look at that. I had no idea.
Leave a Comment or Response