Speech Viewer Logs of Lies
When sighted users test with a screen reader it is common to rely on the visual output — checking to see where focus goes, confirming that controls behave, watching the spoken output in a text log.
The problem is that what you see in those speech viewers is not always what you hear.
Consider how an emoji is represented in a log versus how it is announced. While visually it may be simple, it can be an audible assault for a screen reader user. 👏 is much easier to skim past when looking at a tweet, but harder when it is announced as graphic clickable emoji colon clapping hands sign
.
The same is true for other extended characters, as in the following example…
When we rely on the display of the speech instead of listening to it, we as developers or testers or authors are unaware that ┏ is announced as box drawings heavy down and right
in VoiceOver. Similarly, the related ━, which may look like an em-dash, is announced as box drawings heavy horizontal
.
If I just relied on the VoiceOver speech viewer, those captions would have been much easier to type and also completely inaccurate.
Demonstration
Obviously these characters are exceptions. Using extended characters always comes with risk, but sometimes even the most mundane text can have an unexpected announcement. I made a quick demo with common content I see on the web:
See the Pen PoNYREO by Adrian Roselli (@aardrian) on CodePen.
Here is how that content is recorded in the JAWS Speech History window:
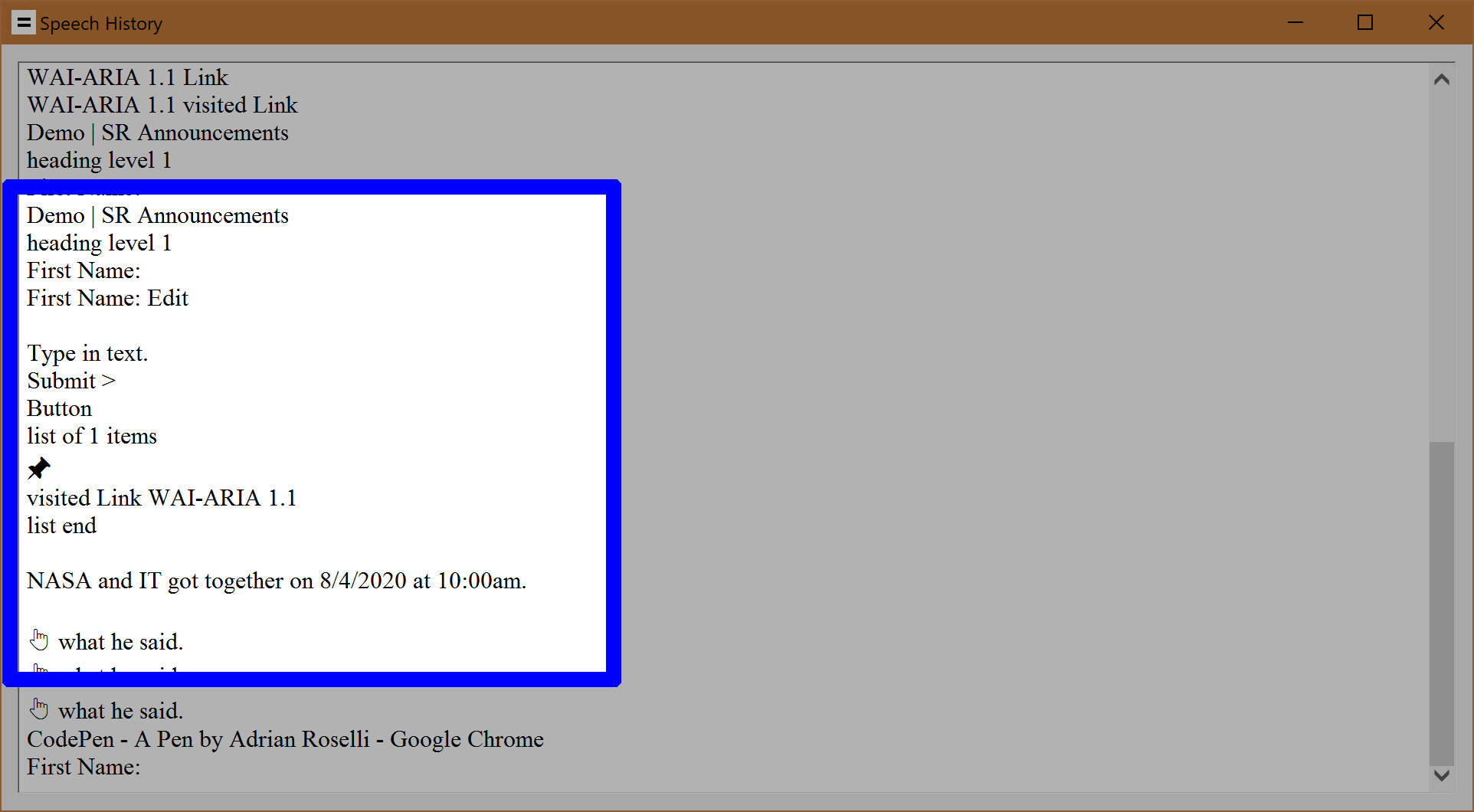
Here is how that same content sounds when spoken — I have added captions that reflect the full announcement, so please enable them and read along as you listen:
Transcript
Demo vertical bar ess are Announcements heading level one
First Name colon
First Name colon edit type in text
Submit greater button
list of one items
pushpin
visited link why dash ARIA one point one
list end
blank
NASA and it got together on eight slash four slash twenty twenty at ten AM
blank
white up pointing backhand index what he said
I want to impress upon you, dear reader, that I am only using JAWS because it was quickest for me. Each screen reader will have slightly different heuristics for how these are announced. I simply do not have time to record them all. This post is about assumptions regardless of screen reader.
Takeaways
Do not use this as justification to try to override what a screen reader says. I noted this on Stack Overflow, back when I was wasting too much time there. It has come up on the WebAIM list many times. I have to explain it to clients on the regular.
If you read my post Stop Giving Control Hints to Screen Readers then you already know trying to tailor content for screen reader users can be problematic. Similarly, forcing your preferred pronunciation or phrasing is a bad idea and should never be done (unless backed up by user research and a darn good use case).
All that out of the way, I see two risks from being unaware of what a screen reader is actually saying:
- QA teams rely on the output matching a speech log;
- verbose interfaces (that sometimes hide important cues).
I have worked with QA teams who send something back to developers because it does not exactly audibly match a provided screen reader log. Often that log is from a different screen reader / browser pairing or a customized set-up not used by QA.
Similarly, if as a developer all I do is ensure the extended characters (emoji, math symbols, etc.) show up in the speech viewer but do not confirm how they are announced (if at all), I can create an unusable interface.
Screen readers offer settings that let you control how verbose they are when encountering punctuation, certain characters, abbreviations, acronyms, or even words. A skilled screen reader user may take advantage of those features, but you cannot count on users doing it and you cannot suggest that as a fix.
What to Do?
Pay attention to times, dates, currency, punctuation, special characters, emoji, math symbols, common (and uncommon) abbreviations & acronyms, and so on. Be aware how they announce across all screen reader and browser pairings that will view them.
Other steps:
- run the screen reader with default settings (barring special cases);
- do not test a screen reader with your audio muted;
- do not rely on the speech viewer / log;
- be wary of any automated test that provides you with a log of screen reader output.
If you are working with multilingual content (truly multilingual, not just the word panini in a description of your lunch) then be sure the lang attribute and the appropriate values are in place. This will help limit incorrect pronunciation from incorrectly marked-up content.
Update: Later that afternoon…
The problem with hyperbolic headlines is they can lead to overly-broad statements on Twitter, such as when I first shared this and suggested that you might be doing it wrong if not listening to the output. While Steve gave it the appropriate wary emoji, the following response drives home the point:
Hmm. I rely on the text output, but I'm also deaf, so…
One of the benefits of the de facto peer review in accessibility is when people point out a flaw in your over-simplified (character-constrained) conclusions. Making sure comments are enabled on your posts and replies allowed on your tweets is a good way to be certain you are not lost in an echo chamber of one.
Similarly, folks can identify other use cases that you failed to mention:
Also, the text log is faster than audio announcements (depending on speed of audio). So some announcements may show up in the log, but the user will never hear them due to live regions and other announcements that mess with the announcement queue.
Considering I have seen this happen (QA signs off on a thing, even though thing is never announced due an unnecessary live region interrupting it), it should have occurred to me to include it in the post.
Update: 24 August 2020
This is a great point about JAWS and which likely applies to the other screen readers (namely that text viewers are not QA tools, they are there to support end users).
The Text Viewer and History Mode in JAWS were not designed for QA. The Text Viewer was designed for teachers and parents and the History Mode was for the JAWS user. As Adrian said, users can change a lot of settings like punctuation, number processing, etc. Have real users test.
Update: 17 January 2022
Steve Faulkner explains a bit of why and how emoji are announced differently across screen readers in his post short note on emoji text alternative variations.
The following table has examples of some (of the many) emojis and how they are described in text by some popular screen readers. Note that there are differences in how they are described in some cases:
- “grinning face” is also “beaming face”
- “beaming face” is also a “smiling face”
- “open mouth” is described by JAWS/Narrator but not by NVDA/VoiceOver
- “big eyes” are described by NVDA/VoiceOver but not by JAWS/Narrator
- “cold sweat” is “sweat” and also “sweat drop”
There is more detail in the post of course.
Update: 30 January 2022
Steve pressed Ctr+Alt+↓ 5,400 times to gather all the JAWS announcements for Unicode characters. Broken up into a series of tables: Symbol text descriptions in JAWS.
A few days later, Steve pressed Ctr+Alt+↓ 3,900 times to gather all the NVDA announcements for Unicode characters. Broken up again into a series of tables: Symbol text descriptions in NVDA
At least now when you read the text output of JAWS or NVDA screen reader speech you will be able to understand how those special characters are actually announced to users. To head off a question, I have no idea if JAWS Inspect already represents characters as they are announced or only uses the symbol Steve has confirmed that JAWS Inspect outputs symbols.
Update: 30 April 2024
Francis Storr has gathered the techniques to capture text from screen readers across platforms, something I failed to do above. Via Bruce Lawson.
Update: 31 March 2025
Windows Narrator is planning to add “speech recap,” which is essentially a log of what Narrator announced.
Narrator key + Alt + X will launch a speech viewer with the last 500 strings Narrator spoke. Narrator key + Ctrl + X will copy the last spoken phrase to your buffer.
Update: 24 November 2025
I finally got around to capturing Narrator (with Edge).
If the focus appears to be ahead of what is being announced, that’s how I experience. It’s not video lag. It also ran some stuff together, like the end of the heading and the field label and also the ARIA link that it split into two and inserted the awkward pause.

Update: 7 April 2026
Eric Eggert makes related points in his post Screen readers are not testing tools.
This complexity means that they are not as straightforward to use as people make it out. “Just test with a screen reader” can have unintended consequences.
He runs through different ways authors and testers who are unfamiliar with screen readers tend to over-complicate based on their own lack of familiarity. This can result in unusable interfaces and / or false positives in WCAG reviews.
I have no opinion on Polypane since I don’t use it. I’m only saying that because his post has a referral link to Ploypane and I simply don’t know it.
3 Comments
There is a solution to these kinds of problem. Certainly all web pages should go through QA and improvements be made so far as possible from their input. But unless you have an expert accessibility consultant on the team (which is not usual), then the next step is then to send the page to an external accessibility audit consultant for them to test.
They will use screen readers on it and listen to what the reader actually says, they won’t look at logs which as pointed out are not helpful. (You also need to invest in having them test on both desktop screen readers and screen readers on mobile devices, as they produce different results.) An experienced audit consultant will also find any other accessibility defects on the page, to help users with other disabilities besides being blind. They have the expertise to do the whole job for you – they do this kind of work full time, not just as a small bit-part among all the other kinds of testing to be done.
Some very good observations here. I’d like to mention a couple of omissions.
First of all, screen reader announcements are typically handled by a system-level speech synthesiser. There are usually various ‘voices’ to choose between, to represent different dialects or other preferences.
The pronunciation heuristics that each ‘voice’ follows are not the same, even with different voices in the same ‘dialect’ from the same vendor.
Example: We have products for a medical context where the string “IV” is announced as “four” by some voices and “roman four” by other voices using the same screen reader. Both are wrong in our case. (We need the idiomatic abbreviation for “intravenous”, which is simply the announcement of the two letters).
So… testing on different screen readers will not reveal the full scale of the problem – and in any case, there is little that can be done by the content creator (or web developer) to fix it which wont compromise the output on (say) a Braille device. So testing widely might reveal more pronunciation issues, but we still have no way to solve them.
As the article above points out the best practice is not to dictate phonetics, it is to indicate clear semantics, but we lack a mechanism to do this. Sometimes the sequence :) is not a smiley, and sometimes I want “IV” read out as two letters. Sometimes O2 means oxygen, sometimes “O-squared” is intended. How do I specify these things?
The W3 pronunciation task force was set up to address some of these issues from a standards point of view, and I encourage all readers here to support or even contribute to their efforts, but the problem and its solution lies primarily with speech synth vendors, not the AT vendors or the content creators.
The primary speech synth vendors are Microsoft, Apple and Google, all of whom have made speech synthesis a part of their operating systems. I don’t get the impression that the teams involved in these technologies are even aware that their speech synth offerings have these significant accessibility failures, and they won’t find out if we complain only to Freedom Scientific, or NVDA, or blame the web developers.
All three of the main speech synth vendors offer quite sophisticated accessibility features at a system level, but none of them tackle the problem of poorly guessed screen reader pronunciation. The way that time values are announced is particularly uneven, and time values are a rare case where you can indicate which field refers to which value. In practice, hours, minutes and seconds are often announced wrongly – even if you take the trouble to specify a well-formed
datetimeattribute.So how do we – as web content and accessibility professionals – apply pressure at the right (and most effective) place to the appropriate teams at Microsoft, Apple and Google to quit their ‘clever’ guessing, and give content creators a modicum of semantic control over how emojis, dingbats, abbreviations, acronyms, units, technical values and the like are intended to be treated?
A further point about multilingual support.
The
langattribute is often ignored, especially if the string for pronunciation is found inside an aria attribute, or a live region. Try it! We find dismal results on many browsers. Safari seems to ignorelangaltogether – the system speech synth language setting overrides everything in the markup.Again, knowing that there are problems with screen reader pronunciation is of questionable value if we have no way to fix them. What is the business case for running tests for problems which have no solution?
Leave a Comment or Response