WayBack Machine Handler for Your 404 Pages
 Last week I mentioned that the Internet Archive WayBack Machine had released a feature to allow custom URLs for on-demand archiving. That wasn’t the only coolr feature it announced.
Last week I mentioned that the Internet Archive WayBack Machine had released a feature to allow custom URLs for on-demand archiving. That wasn’t the only coolr feature it announced.
Another nifty feature that the Internet Archive offers is the ability to enhance your 404 pages. You can provide a visitor to a missing page with a link to that page in the WayBack Machine: Free “404: File Not Found” Handler for Webmasters to Improve User Experience
A nice feature of this service is that if there is no page with the current URL (that the user requested) in the WayBack Machine archive, then no link will appear and your 404 page will appear unblemished.
While some businesses might not want to direct people to an archived version of a bio for a long-gone staff member, or perhaps product details that are no longer correct, there is plenty of value for governments, not-for-profits, and other organizations who, ostensibly, shouldn’t be removing any information. Organizations whose sites undergo regular upheavals, whether by changing the entire site structure, changing platforms, or generally just not building redirections during normal content restructuring, can offer a better experience to users.
The code is pretty simple (though I recommend against the self-closing div in the Internet Archive example, as some WYSIWYG editors will create the closing tag and wrap it around the script block):
<div id="wb404"></div> <script src="https://archive.org/web/wb404.js"></script>
Granted, it relies on client-side script, and there is a chance some browser configurations will block it, but the benefit may outweigh those concerns.
To test it, I hopped into our web content management system at Algonquin Studios (QuantumCMS) and dropped that code block into the content area of the generic 404 page. Then I scoured the site for a page that we hadn’t updated or redirected during one of our site overhauls and that also existed in the WayBack Machine.
Until I can get around to redirecting that missing page, you can see the effects of the 404 handler from the Internet Archive. If you are reading this after I made that redirection, here’s a screen shot of how the link appears on the page:
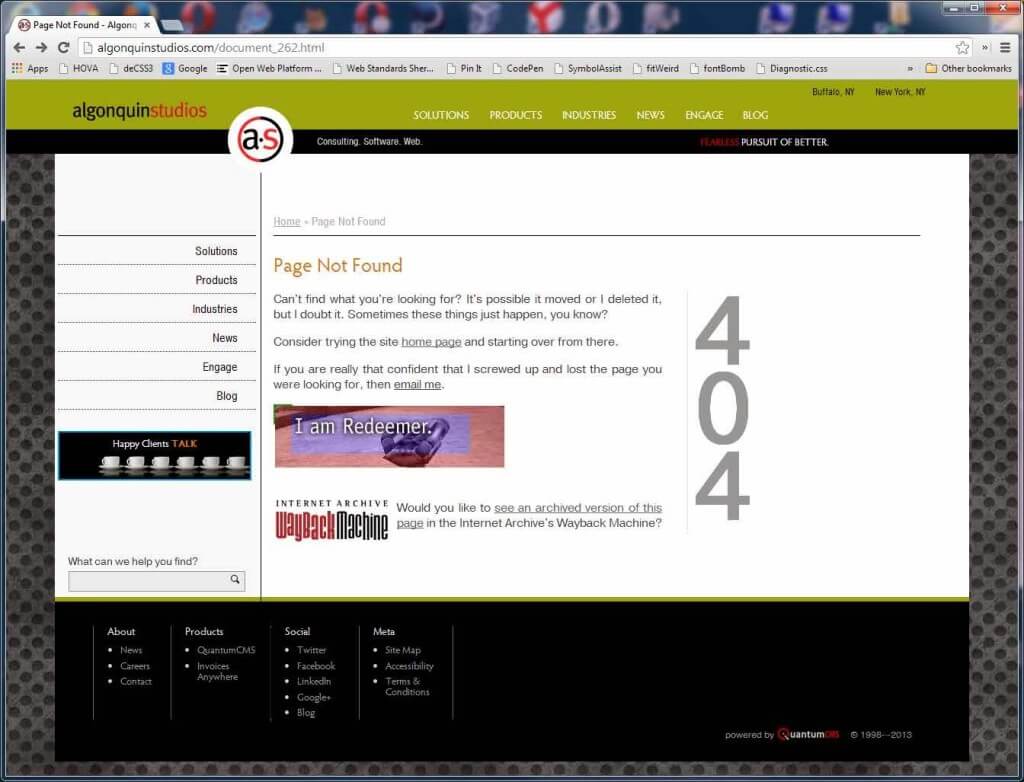
That’s it. Simple, straightforward, and potentially very useful to your visitors.
Update: November 13, 2013
Thanks to the story Conservatives erase Internet history, we know that the Internet Archive’s WayBack Machine can be pretty easily cleared of historic pages just by updating a site’s robots.txt file. While I would expect that the effect should only kick in from the date of the edit of the robots.txt file forward, that doesn’t appear to be how it works.
I guess this casual tweet from my one of my partners at Algonquin Studios was more prescient than I thought, though in the opposite direction:
@aardrian unless Wayback captures that legally indefensible policy that made you take down the page. Or a hacked version of the site.
— stevenraines (@stevenraines) November 13, 2013
Leave a Comment or Response