Google wants to speed up the web, and it has a plan:
For many, reading on the mobile web is a slow, clunky and frustrating experience – but it doesn’t have to be that way. The Accelerated Mobile Pages (AMP) Project is an open source initiative that embodies the vision that publishers can create mobile optimized content once and have it load instantly everywhere.
Ramble Ramble Ramble
I’ve been wanting to dive into this topic all weekend. I started this post, I stopped this post, I came back to it, I let it lapse. In the end, others have already written thoughts about AMP HTML that are better than I could have rambled through on my own, so I am collecting some of them here (via links and some quotes).
Right off the bat, if you use the AMP project page to get a sense of how capable Google is of doing this right, you may become a little deflated. For starters, it fails on the accessibility front, lacking alt text on images, a lang attribute on the <html> element, controls on its opening video, and sufficient text contrast. It also seems to demonstrate just why we want faster pages by itself weighing in at 44MB over 124 requests, taking nearly 6 seconds to load as Mat Marquis demonstrated:
But that’s just the marketing page. That isn’t the AMP HTML spec itself (though maybe it’s trying to prove its own value?). Thankfully you can find it on GitHub and will see this very comforting opening (if you’re into standards-based development):
AMP HTML is a subset of HTML for authoring content pages such as news articles in a way that guarantees certain baseline performance characteristics.
Being a subset of HTML, it puts some restrictions on the full set of tags and functionality available through HTML but it does not require the development of new rendering engines: Existing user agents can render AMP HTML just like all other HTML.
Once you wade into the spec itself you will find that it does not, in fact, exist as a sub-set of HTML, but essentially a forked version. When you start minting new attributes that already exist in HTML, but for completely different purposes (in one case, placeholder), you have to agree with Jeremy Keith’s response:
Um. At some point, you may have to stop referring to AMP HTML as a subset of HTML and just say it’s a different language, because, well, if you invent attributes like this, it is.
If you read that entire bug thread, you might have a better sense of how there is little attempt here to truly exist as a sub-set of HTML.
For example, I feel that <amp-img> is an over-engineered replacement for <img>. While it allows srcset, I think leaning on the entire responsive image spec would be easier to track and promote consistent use. I also believe lazy-load feature could be explored using the <template> approach described by Christian Heilmann.
There are other places where the requirements fly in the face of good UX, such as this bit on defining the viewport for responsive layouts to prevent zooming (though there is a bug open to correct it [update below]):
AMP HTML documents MUST
[…]
contain a <meta name="viewport" content="width=device-width,initial-scale=1,minimum-scale=1,maximum-scale=1,user-scalable=no,minimal-ui"> tag inside their head tag.
[…]
There are other bugs tagged accessibility, and I hope to see more added to the list as there are a lot of curious decisions in the spec right now.
Even Longer (But Less Rambly) Reads
Tim Kadlec has a good post, AMP and Incentives, that I think sums up much of this rather nicely:
AMP isn’t encouraging better performance on the web; AMP is encouraging the use of their specific tool to build a version of a web page. It doesn’t feel like something helping the open web so much as it feels like something bringing a little bit of the walled garden mentality of native development onto the web.
Jeremy Keith has written a sort of FAQ in AMPed up that, in addition to being a great list of questions, has a great opener:
That error message (Sorry, this page is not valid AMP HTML.) is exactly the reason (well, one of many) that XHTML2 never went anywhere. Malformed HTML still gets rendered, malformed XHTML2 did not. That strictness prevented it from gaining any traction.
So yeah.
Update: November 17, 2016
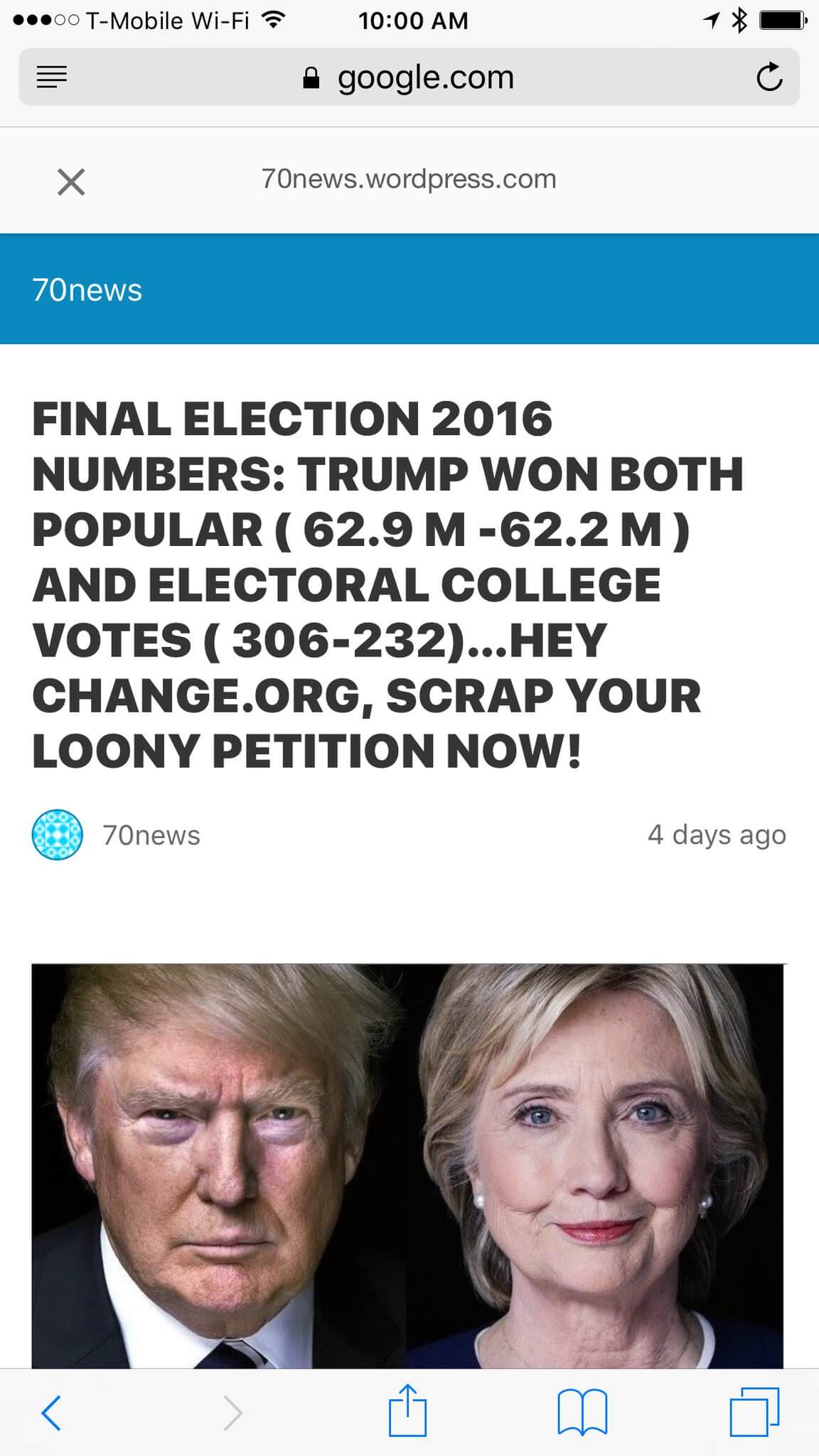
Google’s AMP lies to us about news sources, owing to the Google.com URL:
Boy, if only Baidu belonged to some standards body that could help prevent this kind of fracturing across the web. Oh wait, it does. Just like Google.
Update: January 18, 2017
Kyle Schreiber has a post, The Problem With AMP, that while not presenting anything brand new does remind us that in well over a year AMP has not quite gotten there. Granted, all standards processes take forever, but at least anyone can participate and they are mostly consistent when applied. His post does remind us that https://encrypted.google.com/ exists and is a viable search alternative if you want to still use Google.
I also came across this piece by Jonathan Schofield titled Trump, Google’s AMP Project, and the law of unintended consequences. He details his own struggles with trying to find the original, canonical article he is reading through AMP and finds an iframe lurking in the midst.
Update: March 8, 2017
Going on right now is the AMP Conf, which is being live streamed if you have the time to watch. I do not have the time to watch, but Tim Kadlic watched the AMP & the web platform talk and wrote some of his thoughts at AMP and the Web.
He notes that the panel, overall, claims that organizations are not choosing AMP for performance reasons, but for SEO reasons. Being an AMP page gives it a badge and a priority location in the carousel.
Sadly, this is corresponds to why I have found myself using Google as a search engine less and less. I want results for my query, not results based on which pages get promoted for following Google’s own technical requirements.
Update: March 13, 2017
Jeremy Keith attended the AMP conference:
This is one of the reasons why AMP feels like such a bait’n’switch to me. […] But the big difference, we were told, was that you get to host your own content. That appealed to me much more than having Facebook or Apple host the articles. But now it turns out that Google do host the articles.
Update: May 22, 2017
The Register has an opinionated piece about AMP, as suggested by its title: Kill Google AMP before it KILLS the web. For good measure, it also has “bad_bad_bad” in the URL.
It does not hold back:
Google’s AMP is bad – bad in a potentially web-destroying way. Google AMP is bad news for how the web is built, it’s bad news for publishers of credible online content, and it’s bad news for consumers of that content. Google AMP is only good for one party: Google. Google, and possibly, purveyors of fake news.
TechCrunch isn’t as overtly anti-AMP, but it does make an observation about Google’s I/O event:
[T]oday Google is introducing coding for three new ad formats. […] [I]t’s no surprise at all that [Google’s] efforts to improve the mobile user experience have moved into improving the mobile advertising user experience.
John Gruber reiterates his dislike of AMP:
It implements its own scrolling behavior on iOS, which feels unnatural, and even worse, it breaks the decade-old system-wide iOS behavior of being able to tap the status bar to scroll to the top of any scrollable view. AMP also completely breaks Safari’s ability to search for text on a page (via the “Find on Page” action in the sharing sheet).
Pixel Envy also gives us a perspective worth noting:
[W]e cannot ignore Google’s slow takeover of the web. The world wide web is slowly becoming a Google product, and that’s just as fundamentally flawed as if the web were a division of Comcast.
Ethan Marcotte points out two troubling developments (Stamp and a framework), and echos what I have been arguing all along — just use a set of guidelines that are based on standards.
What’s more, AMP’s scope is expanding. There’s talk of an upcoming AMP variant called “Stamp”, an extension of the framework that’d provide a Snapchat-like, media-friendly experience for publishers (and their advertisers). But I’m also given to understand Google’s about to position AMP as a general site-building framework, similar to Bootstrap or Foundation. […]
[…]
[…] But that aside, I can’t help but wish Google had approached their “Accelerated Mobile Pages Project” differently, perhaps as a set of guidelines. Rather than creating a parallel HTML standard, and leveraging Google’s own search results to incentivize adoption, I wish the AMP had defined a set of criteria that could’ve been validated by, say, Google’s own Lighthouse project.[…]
Jeremy Keith has called out Google’s constant mis-characterization of how AMP pages appear in search results:
At AMP Conf, the Google Search team were at pains to repeat over and over that AMP pages wouldn’t get any preferential treatment in search results …but they appear in a carousel above the search results. […] This is the only reason why The Guardian, for instance, even have AMP versions of their content—it’s not for the performance benefits (their non-AMP pages are faster); it’s for that prime real estate in the carousel.
This is, in my opinion, the only reason that AMP still has any legs with publishers. It certainly isn’t from guaranteed speed or control over hosting. It’s because Google has a lock on the search engine space and publishers have no choice but to play ball.
Ethan Marcotte tears apart the notion that AMP is open in anything but the most basic sense.
So, yes. The HTML standard does allow for the creation of custom elements, it’s true, and AMP’s license is quite liberal. But spend a bit of time with the rules that outline AMP’s governance. Significant features and changes require the approval of AMP’s Technical Lead and one Core Committer—and if you peruse the list of AMP’s Core Committers, that list seems exclusively staffed and led by Google employees.
Those who play in open source already know that putting something on GitHub and telling people that they contribute is usually an easy way of dismissing those who have valid concerns with a project. It immediately limits participation to only those who have the free time and the specific technical skills, which will never compete with the corporate team paid to know the technology and staff the project.
Update: November 21, 2017
Good thing AMP has guaranteed smaller pages without all the cruft!
This ⚡️AMP page on The Daily Beast weighs 2.7 MB, performs 250 HTTP requests (90 of which are JavaScript), takes 16 seconds to load, shows 10 ads, and includes over 20 trackers.
Good thing AMP doesn’t require a specific browser!
This is what I get on a slow connection when I click on links in the Google app and immediately ask the custom tab to open in Firefox (I have to wait a bit)
This does not happen if my default browser is Chrome and seems to be an AMP issue.
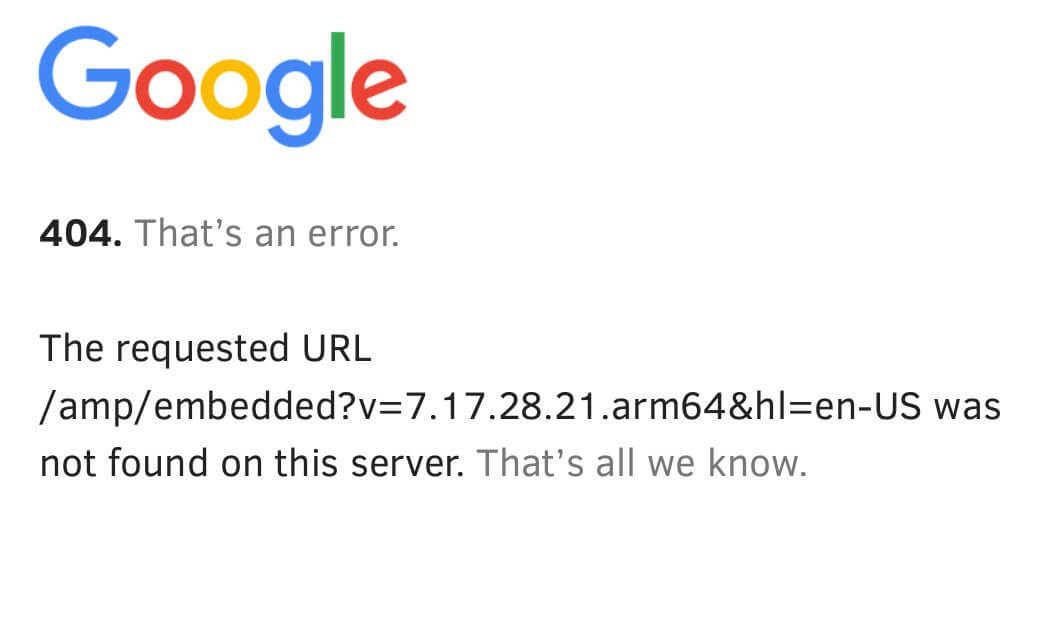
Oh, hey, copying that 404 URL into chrome works great.
What the fuck, Google? You're giving 404s based on the browser now?
At least have the decency to give an unsupported browser message so I know what's going on.
Update: December 28, 2017
Remember that Ajit Pai used Google AMP to justify killing Net Neutrality (only one of many arguments, of course):
And many [Silicon Valley companies] thrive on the business model of charging to place content in front of eyeballs. What else is “Accelerated Mobile Pages” or promoted tweets but prioritization?
Ethan Marcotte builds on that to discuss zero-rating and net neutrality:
The more I’ve thought about it, I think there’s a strong, clear line between ISPs choosing specific kinds of content to prioritize, and projects like Google’s Accelerated Mobile Project. And apparently, so does the FCC chair: companies like Google, Facebook, or Apple are choosing which URLs get delivered as quickly as possible. But rather than subsidizing that access through paid sponsorships, these companies are prioritizing pages republished through their proprietary channels, using their proprietary document formats.
Update: January 8, 2018
This is not a unique sentiment.
AMP brands itself as good for the web and improving user experience, but ultimately it’s just proven itself as a way to game search results with a side effect of speed sometimes.
Update: January 9, 2018
AMP may lean on a web standard for its caching, which I of course applaud.
We embarked on a multi-month long effort, and today we finally feel confident that we found a solution: As recommended by the W3C TAG, we intend to implement a new version of AMP Cache serving based on the emerging Web Packaging standard. Based on this web standard AMP navigations from Google Search can take advantage of privacy-preserving preloading and the performance of Google’s servers, while URLs remain as the publisher intended and the primary security context of the web, the origin, remains intact. We have built a prototype based on the Chrome Browser and an experimental version of Google Search to make sure it actually does deliver on both the desired UX and performance in real use cases. This step gives us confidence that we have a promising solution to this hard problem and that it will soon become the way that users will encounter AMP content on the web.
You will note I explicitly did not link to the AMP version of that page (which performs worse than the AMP page simply because of third-party scripts and fonts that could, you know, just be excluded).
I intentionally left the weird <span>s in place in the underlying HTML of that quote from the AMP page (which are different and use more characters than the non-AMP version of that page).
Separately, an open letter appeared today asking Google to be more transparent and stop promoting AMP pages in search results.
If Google’s objective with AMP is indeed to improve user experience on the Web, then we suggest some simple changes that would do that while still allowing the Web to remain dynamic, competitive and consumer-oriented:
Instead of granting premium placement in search results only to AMP, provide the same perks to all pages that meet an objective, neutral performance criterion such as Speed Index. Publishers can then use any technical solution of their choice.
Do not display third-party content within a Google page unless it is clear to the user that they are looking at a Google product. It is perfectly acceptable for Google to launch a “news reader”, but it is not acceptable to display a page that carries only third party branding on what is actually a Google URL, nor to require that third party to use Google’s hosting in order to appear in search results.
Update: February 19, 2018
Google has announced AMP Stories and demonstrated that it has not listened to developers at all, instead looking to compete with Apple News and otherwise do its own thing. Tim Kadlec offered his perspective:
So, to recap, the web community has stated over and over again that we’re not comfortable with Google incentivizing the use of AMP with search engine carrots. In response, Google has provided yet another search engine carrot for AMP.
Luke Stevens (unironically) has a Twitter thread about AMP and open standards:
I've been thinking about implications of Google's AMP ambitions for web standards, and can't shake the This Is Getting Worse feeling.
So, time for some AMP GAME THEORY.
j/k but seriously here are my thoughts on AMP. 1/?
I am also concerned that, with enough forced “traction” from AMP use, Google will use its influence at WHATWG (which is primarily browser makers) to attempt to standardize its self-serving practices in WHATWG’s version of HTML. It will cite implementations of its own diktat as an example.
Google keeps claiming it is trying to foster an open web. Evidence and ongoing behavior constantly contradict that assertion.
Frankly, I like Dave Rupert’s approach to dealing with the AMP Stories carousel:
Back in my day, we'd all have tried really hard to GOATSE the new AMP Stories carousel…
This new spec will be a powerful way for developers to create more engaging, interactive, and actionable email experiences.
This is a terrible idea. “Interactive” is a code for auto-playing video and animation in my email; “actionable” is code for forms and weird controls in my email.
Time to start pulling Gmail out of the web interface and into a UI where I can auto-delete AMP email.
Update: March 19, 2018
Tim Kadlec does some performance comparisons between AMP pages (with and without the AMP cache) and the canonical non-AMP pages (that are not even trying to be small). Of course the AMP pages are faster, but the duplicate fat pages are still there.
If we’re grading AMP on the goal of making the web faster, the evidence isn’t particularly compelling. Every single one of these publishers has an AMP version of these articles in addition to a non-AMP version.
Update: September 19, 2018
I don't think you can build a thing entirely closed at one company, intended to exert influence over the broader ecosystem, and then call it an open standard or project. AMP is not "part of the open web", no matter what Google says. theverge.com/2018/9/18/17871666/google-amp-open
Update: March 23, 2019
Unless your page is loaded from the AMP Cache (which it won’t be when linked from Twitter), your non-AMP site can be faster. In other words, AMP is no guarantee of a faster experience for users. Especially if you want them to do things like leave comments.
According to Google’s own Page Speed Insights audit (which Google recommends to check your performance), the AMP version of articles got an average performance score of 87. The non-AMP versions? 95.
[…]
The mean time to first byte for the AMP page is 1005ms, and for non-AMP it’s 989ms. […]
The time until the page is visually complete for AMP is 2166ms, and for non-AMP it’s 1955ms, which is a difference of 211ms or 9.7%, a much larger discrepancy than that on the server-side.
[…]
This is the fruit of weeks of labour converting the site: a slower, less interactive, more clunky site.
Update: March 26, 2019
Ars covers AMP embeds in email, but does it in a terribly non-critical way (as in, it asks no hard questions, it just says it is a thing). The folks who left comments, on the other hand, were a bit more cautious. Each paragraph below is from a different comment.
There had better be a setting to disable this, I don’t want the equivalent of flash hacks and autoplay videos filling up my mailbox.
I’m sure there’s zero chance of this being abused in any fashion
Shouldn’t the headline be “e-mail viruses reborn, as Google brings Advanced Malware Propagation¹ to your inbox”?
Question: who is asking for this?
It sounds like a wet dream for advertisers and malware writers, but very little in the way of value to users. Looks like they’ve given up even trying to pretend they’re developing these new “innovations” for the benefit of consumers.
Is “rich interactivity” what we non-abhumans refer to as “even more ads; probably a tracking risk” in our nightmare cyberpunk dystopia?
Update: May 2, 2019
It's been said before but it would be so good for the web if pages with a Lighthouse score over say, 90 could get into that top search result area, even if they're not built using Google's AMP framework. Feels wrong to have to rebuild/reproduce an already-fast site just for SEO
Seems misleading when I read that an AMP version was "3x faster" with no mention that a key reason for that may be that AMP pages are pre-fetched from Search before you visit them. Prefetching makes any kind of site faster, but only AMP sites are given that advantage (…afaik?) twitter.com/scottjehl/status/11239
Update: May 3, 2019
Jeremy Keith points out the mismanaged expectations, even within Google.
First, AMP is positioned as a separate format. Then, only AMP pages are allowed ranking in the top stories carousel. Now, let’s pretend none of that ever happened and act as though AMP is just another framework. Oh, and those separate AMP pages that you made? Turns out that was all just “transitional” and you’re supposed to make your entire site in AMP now.
I would genuinely love to know how the Polymer team at Google feel about this pivot. Everything claimed in this blog post about AMP is actually true of Polymer […].
Update: May 12, 2019
From the AMP face-to-face in March, some notes on accessibility:
Many of the components are not sufficiently accessible.
Accessibility tree – usually used by browsers – they understand whatever HTML element does.
AMP doesn’t rely on native elements enough
Media Player is a real concern. Controls show up as list boxes rather than buttons
Same kinds of issues for the carousel
[…]
The AC would like all components to meet WCAG 2.1 before release
By the AMP Contributor Summit – produce a roadmap and timetable for raising the existing components up to the expected standard
AI(): reach out to TSC/Accessibility WG and ask for audit of existing components.
AMP documentation should specifically show how to make elements accessible
[…]
AMP Validator should fail pages which do not pass automated a11y tests (100% score on lighthouse?)
Byproduct – AMP Caches should not serve pages which do not validate against a11y tools
Offer our help to the WG
AI(@tobie): organize meeting with a11y WG. Either invite them to AC meeting or join one of their calls.
[…]
Update: May 15, 2019
Terence Eden joined the AMP Advisory Committee. He is easily as anti-AMP as I, so I respect his willingness to get involved to try to shepherd the inevitable. He gathered his thoughts from the AC meeting. You should read the entire thing, but I am quoting part of his conclusions here.
As I said in the meeting – if it were up to me, I’d go “Well, AMP was an interesting experiment. Now it is time to shut it down and take the lessons learned back through a proper standards process.”
I suspect that is unlikely to happen. Google shows no sign of dropping AMP. Mind you, I thought that about Google+ and Inbox, so who knows!
Terence raises a good point. Google is fickle. I look forward to seeing AMP on Killed by Google. In the meantime, I get around the AMP news carousel issue by using Duck Duck Go as my search engine in all my browsers.
Update: May 29, 2019
Andrew Betts points out that the portals proposal seemingly exists solely for the purpose of enabling AMP’s carousel feature.
This enables Google to continue to exist after the destination site (eg the New York Times) has been navigated to. Essentially it flips the parent-child relationship to be the other way around.
He goes into the UX and commercial impacts, and wraps it all up with a look at the coercion Google is using.
I was not smart enough to make that connection, but I have shared my opinions about portals.
2000: Internet Explorer 5.5 introduces page transitions, is widely ridiculed.
2018: Chrome introduces page transitions, is considered ‘cool’.
Perhaps all of this is moot. The W3C, which is made up of browser vendors as well as other interested parties, has ceded control of HTML to WHATWG, which is made up of browser vendors. With Google controlling the engine that now powers most of the browsers on the web, and Google the de facto powerhouse of WHATWG, it can just force through AMP (and portals).
Way back in (checks top of post) 2015 when I wrote this post, I raised concerns about the accessibility issues with AMP. On May 19 of this year I added an update that looked specifically at the accessibility issues four years later.
This is why I was not particularly surprised when Ethan Marcotte, in his post Amphora., identified that AMP Stories had its own set of accessibility problems. He embedded clips from using the AMP Stories demo in a screen reader.
It is a mess. A mess for which there is no excuse because people have been raising accessibility failures on carousels (which is all AMP Stories seems to be) for years. There is literally no excuse for this utter, embarrassing failure on Google’s part to even make a passing effort.
That didn’t stop someone from trying to clean up the message (not the effort):
@beep thank you for highlighting a11y issues related to AMP Stories. Definitely not intentional. We take this feedback, and a11y very seriously and need to do better.
Stay tuned is literally the opposite of managing expectations, let alone holding oneself accountable. The phrase intend to follow the WCAG closely is a weasel phrase that makes no commitment to be WCAG-compliant.
I am sure you can understand why I don’t take that message seriously (despite its serious use of the word “seriously”). In four years they keep dropping the ball. Spinning up an issue on GitHub in the name of transparency will not fix it. Talking about it in an advisory committee meeting (the only one to date) won’t either.
The only demonstrably effective way to fix AMP’s ongoing accessibility shortcomings (in process and code) is to not use AMP.
Update: September 4, 2019
In Google Is Tightening Its Grip on Your Website, the author drives home the point that AMP only persists because Google uses it as a key signal to promote pages in search results.
Google has argued that AMP is good for the web as a whole and that it cares about journalism. I agree that the company has invested heavily in the ecosystem and that AMP has helped make the web faster — but if Google genuinely cared, it would rank pages based on speed alone, not whether they use some special format of HTML.
In Opening up the AMP cache, Jeremy Keith proposes that Google open the AMP Cache to non-AMP pages, perhaps giving preference to fast, accessible pages.
What if Google were allowed to host non-AMP pages? Google search could then prerender those pages just like it currently does for AMP pages. There would be no privacy leaks; everything would happen on the same domain—google.com or ampproject.org or whatever—just as currently happens with AMP pages.
I haven’t heard of it gaining any traction over a month later.
Update: December 5, 2019
Each of the following links are to anchors in the same post.
That quick checklist belies the real value of the post — lightly and simply explaining the conceit that is Google AMP’s reason for being. It starts off looking at Hacker News comments in support of a 2018 post, Google AMP Can Go To Hell.
In a new thread about this latest post on Hacker News, a few people don’t care and a few recognize that Google created AMP to address a problem that Google itself partially created. Only a couple understand that Google could have simply published performance standards and avoided AMP altogether (assuming Google was sincere in its message that AMP was about perf).
Update: February 18, 2020
In the post In search of the amp.dev search, two developers write about their efforts to build a search for the AMP.dev site. It is no doubt an impressive effort using AMP technologies, even if the limitations are self-imposed. The conclusion sums up the requirements:
The cool thing about this is that we integrated the search without a single line of JavaScript (except the Service Worker part). Just by making use of AMP’s existing components we could integrate useful features like auto-suggestion and infinite scrolling, which would be quite challenging to implement otherwise!
Given that sites has relied on search for decades without JavaScript (mine does not use it at all), and given that AMP pages are supposed to be blazing fast, one can assume a server round-trip would not be a big deal. Ostensibly the reason for the effort is to get the auto-suggest and infinite scroll features.
Infinite scroll is an anti-pattern and probably a WCAG failure (though the use of a modal dialog for the search results might mitigate that in the way you can use a blowtorch to light a match). The auto-suggest undoubtedly has value to some users, but native HTML search in modern browsers will offer a list of recent entries. Auto-suggest removes that.
Update: May 5, 2020
AMP is now doing… DRM?
Stuck between keeping content secure and providing a great user experience? The debate is over! We’re introducing a new type of premium experience! Client-side content encryption is a fast and user-friendly solution to protect and serve premium content. All while providing the same level of security as server-side validation!
I’ll leave the security aspects of this to security pros (though in my experience, encrypted things rarely stay that way).
I am more interested in how this experience is better for users. An AMP page is supposed to be smaller. It is supposed to be simpler. In this model, not only does the browser have to download the login form and content, but it has to download the encrypted, or fatter, version of that content. Even if you do not have an account or decide it is not worth your time. You just downloaded a far fatter payload than you would have.
But if you decide to log in, now your phone gets to decrypt all the content. While there are no benchmarks in this marketing release, I think it is fair to say that will use more battery (and may take longer) than just getting the rendered static HTML page. Particularly if you are on a low-end phone (as most users are).
Somehow this battery-draining, processor-crunching, device-slowing experience is pitched as a win for… users?
Update: June 26, 2020
I think Zach Leatherman does a good job of capturing the current situation with AMP:
Google is proposing a new standard called WebBundles. This standard allows websites to “bundle” resources together, and will make it impossible for browsers to reason about sub-resources by URL. This threatens to change the Web from a hyperlinked collection of resources (that can be audited, selectively fetched, or even replaced), to opaque all-or-nothing “blobs” (like PDFs or SWFs). Organizations, users, researchers and regulators who believe in an open, user-serving, transparent Web should oppose this standard.
Maciej at Apple frames the Brave post well:
I’m glad to see Brave speaking out agains WebBundle tech (AMP 2.0). This is part of Google’s ambition to serve the whole web from their own servers while pretending it’s coming from elsewhere. It’s also bad for privacy protections, as outlined by Brave in this post. twitter.com/brave/status/129833…
"AMP" is a confusing umbrella (our bad) for 3 distinct things:
– A WC library for speed
– the Search carousel feature
– a related CDN to enable privacy-preserving prefetch
Good to distinguish.
So I ran a Twitter survey (updated with results):
What do you think AMP is?
A WC library for speed: 21.9%
The Search carousel: 23.4%
CDN for privacy pre-fetch: 17.2%
All of the above: 37.5%
Given the respondents are generally more technical, aware of the landscape, this much variance in this HIGHLY SCIENTIFIC poll suggests that the AMP messaging lacks clarity. The answer is all of the above, incidentally.
Inline update on 15 October: The AMP home page says AMP is a web component framework to easily create user-first… websites / stories / ads / emails, cycling through those 4 options with a little animation that ignores my reduced animation settings.
Update: October 15, 2020
Google has moved its AMP marketing site away from ampproject.org and over to amp.dev. The 404 tracker I have on my blog alerted me. I don’t know if the site is new or not, but I can tell you that after taking 20 seconds with my keyboard and getting stuck in that fustercluck of a language selector, I can only say, please do not code your site like the AMP site. It continues to be a paragon of inaccessible code and poorly-executed patterns.
Four years after offering special placement in a “top stories carousel” in search results to entice publishers to use a format it created for mobile pages, called AMP, Google announced last week that it will end that preferential treatment in the spring.
From the referenced Google post:
The change for non-AMP content to become eligible to appear in the mobile Top Stories feature in Search will also roll out in May 2021. Any page that meets the Google News content policies will be eligible and we will prioritize pages with great page experience, whether implemented using AMP or any other web technology, as we rank the results.
The article from The Markup also gives an overview of the history of Google pressuring publishers, expanding AMP to beyond its initial claim, and the reduced benefit for publishers.
Obviously news outlets won’t abandon it yet, but they can at least start to reduce reliance.
Next is to get Twitter to stop adding the AMP switch query string on every tweet in mobile. That alone might dramatically reduce AMP use.
Update: December 17, 2020
Three complaints against Google so far. But the following section on Google AMP stands out in the Texas complaint, which includes Arkansas, Idaho, Indiana, Kentucky, Mississippi, Missouri, East and West Dakota, and Utah.
207. Although Google claims that AMP was developed as an open-source collaboration,
AMP is actually a Google-controlled initiative. Google originally registered and still owns AMP’s
domain, ampproject.org. In addition, until the end of 2018, Google controlled all AMP decisionmaking. AMP relied on a governance model called “Benevolent Dictator For Life” that vested
ultimate decision-making authority in a single Google engineer. Since then, Google has transferred
control of AMP to a foundation, but the transfer was superficial. Google controls the foundation’s
board and debates internally [REDACTED].
[…]
211. Google falsely told publishers that adopting AMP would enhance load times, but
Google employees knew that AMP only improves the [REDACTED] and AMP pages
can actually [REDACTED]. In other words, the
ostensible benefits of faster load times for cached AMP version of webpages were not true for
publishers that designed their web pages for speed. Some publishers did not adopt AMP because
they knew their pages actually loaded faster than AMP pages.
AMP is clearly implicated as one of the tools Google uses to exert a stranglehold on search and header bidding. This suggests it was never about users. It certainly was never about standards.
Update: February 11, 2021
Excerpts from a longer thread:
Let that sink in for a moment. Google is by far one of the biggest online publishers. What they're really saying is that they don't want *other* publishers to have high-quality, search-derived targeting data about you, but they're happy to have and use it themselves.
As I noted in my November update (#41 on this post), Google will soon end preferential placement for AMP pages in its carousel. It may have been partly to position it better to defend in the anti-trust suit I mentioned in my December update. A couple weeks ago the post The End of AMP outlined how this may (hopefully) bring about the end time for AMP.
The author is as curious as I am about whether Google will actually honor this, but the only way we will know is if site owners improve their own pages. Something they may have put off as they focused limited resources on chasing the AMP boondoggle.
It will be interesting to see if Google indeed relies on their own page experience scores or still biases towards AMP […]
[…]
[…] What does this mean for you as a publisher? Simple – get to work right now to ensure that your site has a great user experience AND has a great user experience score. Avoid unnecessary JavaScript, plugins and bloat, and make your site easy-to-use. If you’re currently using AMP, you’ll be able to get rid of that monstrosity in May, and if you aren’t, you’ll now be competing for search positions previously unavailable to you. For publishers, it is a win-win.
If a performant site does not make the carousel, then we have a good indicator Google is still playing its monopoly game.
It claims AMP’s speed benefits were a lie, achieved by slowing non-AMP ads. Among other things. Read the PDF I linked, peruse some of the threads, consider the history of people arguing AMP was antithetical to the open web.
Following are excerpts from some sample Twitter threads.
google… intentionally slowed down non-amp ads to give amp a "comparative boost"? ahem, did google's very-visible-public-engineer-amp-representatives know about this? pic.twitter.com/FxmQk44UaA
it sure seems like everyone was in on the scam, including the super-senior-engineers who were tweeting about it just being a good-natured attempt to make the web faster pic.twitter.com/oDDCIL6nAN
I don't think enough has been made of the discovery that Google's funding of AMP was an explicitly anti-competitive move designed to limit competition from other ad exchanges and what enormous damage this does to Google's credibility with developers:twitter.com/livlab/status/145244…
Why not just stick to web standards and build meat and potatoes web pages that can work with whatever ad exchange you need?
Because Google can also simultaneously exert pressure onto publishers to use AMP to increase likelihood of search ranking performance.
Many of us were skeptical about this particular technology for various implementation reasons (the stated goal of making web pages load faster is pretty non-controversial) but had been willing to believe that the motivation wasn’t solely anticompetitive. That’s dead now.
With AMP as the backdrop of Google’s prior behavior to making the web “better” for only itself, it is easy to understand why any future efforts from Google should be treated with skepticism. The best predictor of future behavior is past behavior, and Google’s anti-trust behavior with AMP is some pretty significant past behavior to consider.
Update: November 19, 2021
Twitter is finally dropping the forced AMP URL redirections on mobile:
We’re in the process of discontinuing support for this feature and it will be fully retired in Q4 of 2021.
I have tweets going back to 2017 grumping about this, so obviously I am pleased. And annoyed it took this long.
On the heels of this, Search Engine Land is dropping AMP completely. With the Google “Top Stories” change, SEL saw a 34% drop in traffic to its AMP pages. Twitter’s change will push that down even more. The hassle of maintaining two distinct “sites” isn’t worth it for them when a few 302 redirects (later 301) will do the job.
For anyone on the fence about dropping AMP from their site, the process Search Engine Land is following should be easy to copy.
Update: August 26, 2022
Tribune Publishing rolled its web properties off from AMP in series. Starting with Baltimore Sun, then South Florida Sun Sentinel, then Chicago Tribune, and finally on New York Daily News. The outcomes showed AMP mattered little, if at all.
Given the higher page RPMs and subscriber conversion rates of a non-AMP page, pulling the plug on AMP looks like an easy win for both programmatic and consumer revenue. And most importantly, we regain full control of the user experience. And that’s perhaps the biggest upside.
Unfortunately, the article is hosted on Medium, the charts rely on color, and the one table of data is an image, which is why I embedded none of it here. At least the author explains it overall.
If you are still on AMP, maybe don’t be.
Update: December 30, 2022
As part of a larger thread on W3C’s transition to a not-for-profit ending its relationship with MIT, Robin Berjon gets into a discussion with Terence Eden, Michael Champion, and Chris Wilson over Google’s role (prompted by an opinion from Terence Eden), and Robin drops this nugget:
@michaelchampion@cdub@danbri
The easy example of this is AMP. If this had been produced by some kind of elected governing body for search, we’d all be expecting them to be kicked out. But not only is the responsible “party” still there, the specific people who caused that harm didn’t face any consequences for it.
I’m not (at all) saying that we should have an electoral system, just that if key parts of the Web have the accountability of post-Brexit Britain, it’s a problem!
A couple follow-ups suggest good-faith efforts to support AMP from the outside may not have been welcome.
4.I don’t know where that leaves us. AMP is a good case study / thought experiment. Sure, no elected governing body would have accepted it. Trouble is, it solved an actual user problem that the web architecture created and never found a consensus fix for. As far as I can tell, Google didn’t so much exploit their power to force AMP on the world as create a palatable solution for users that leveraged and enhanced their own power as well.
@michaelchampion@cdub@danbri
I didn’t say that an elected body would have accepted it or not, just that if the people who made the decision to deploy AMP had been elected we’d have fired their asses.
And your take on AMP is too generous. A group of us actually went to G with a proposal that would have kept AMP alive and helpful but removed the parts that only help G. They only sent lawyers to shut us down. There’s zero room left to believe in good faith on that one, I’m sorry to report.
The good part here is that no one is defending AMP as a current project.
Yesterday The Verge posted Speed Trap, which details the rise and fall of Google’s AMP project. Along with Google’s reputation among developers, publishers, standards wonks, and (from my experience) accessibility practitioners.
The best quote I can pull that ties it all up and should serve as AMP’s epitaph in the Google Graveyard is this closing:
Google is still the web’s biggest and most influential company. But across the publishing industry, it’s no longer seen as a partner. AMP ultimately neither saved nor killed the open web. But it did kill Google’s good name — one not-that-fast webpage at a time.
Google AMP is still out there, however, so it is not truly dead. At least not yet. Instead it will continue shuffling around random publisher sites, waiting for the sprint that finally kills it.
Do Google expect the W3C to update HTML5 by adding their additional elements and attributes?
Because then I don’t think Google understand the purpose of HTML. It is a general document format. It should not carry implementation-specific features such as “amp-boilerplate”, whose very name refers to Google’s project.
Do they think that the name “amp” belongs up there with “content” and “encoding”?
Or do they intend to keep the AMP format separate forever from HTML?
Any updates in the accessibility of AMP? A lot of them ask me if they can use AMP on their sites & I answer that AMP is good for gaining good search rankings & to load the pages in few seconds… but if you ask me if it is completely accessible then I think not..



![249. The speed benefits Google marketed were also at least partly a result of Google’s throttling. Google throttles the load time of non-AMP ads by giving them artificial one-second delays in order to give Google AMP a “nice comparative boost.” Throttling non-AMP ads slows down header bidding, which Google then uses to denigrate header bidding for being too slow. “Header Bidding can often increase latency of web pages and create security flaws when executed incorrectly,” Google falsely claimed. Internally, Google employees grappled with “how to [publicly] justify [Google] making something slower.”](/wp-content/uploads/2015/10/AMP-lawsuit_01.png)

Leave a Comment or Response